
How Good Is Your Model, Really?
How I Learned to Define and Measure Quality as a Model PM

When I first moved from “classic” product management into model-heavy products, the questions I got most often from stakeholders were:
“How good is your model?”
“How did you evaluate quality?”
Underneath the questions was a deeper anxiety given the non-deterministic nature of LLM: If we ship this GenAI thing, how do we know it’s actually good — and stays good?
There are numerous excellent blogs and courses on evaluations already. This post summarizes my learnings and best practices from being a model/genAI PM at scaled companies:
How to define quality differently depending on the use case
How to operationalize evals (offline + online)
How to think about hallucination in a practical, non-hand-wavy way
How PMs (even non-deeply-technical ones) can add real value to the evals system
Start With PMF, Not Models
The biggest mindset shift for me: quality is not a universal property of a model. It’s defined by the product’s PMF.
So instead of asking “Is the model good?”, ask:
“Given this use case and this user, what does ‘good’ look like?”
A simple way to get there is to define a few core evaluation dimensions for each product surface:
Accuracy – Is the output factually correct or faithful to the input/context?
Relevance – Is it tailored to the specific task, user, and scenario, or just generic “smart-sounding” content?
User value – Does it actually help users achieve their goal, in a form they can use?
Trust & safety – Does it avoid disallowed or harmful content that would hurt users or break trust?
Those dimensions stay the same in name, but how they’re applied changes by use case.
Example A: Media Generation
For media generation (images, video, etc.), “good” might look like:
Accuracy – The output follows the prompt; required objects, styles, and constraints are present; there’s no obviously wrong detail (like misspelled text).
Relevance – The output fits brand guidelines or platform norms.
User value – A typical user would actually use this asset for their goal, not dismiss it as “meh.”
Trust & safety – Disallowed content (hate, harassment, sexual content, self-harm, etc.) is avoided, including on borderline prompts.
Example B: AI Coach
For an AI “coach” or assistant that explains or advises, the same dimensions translate differently:
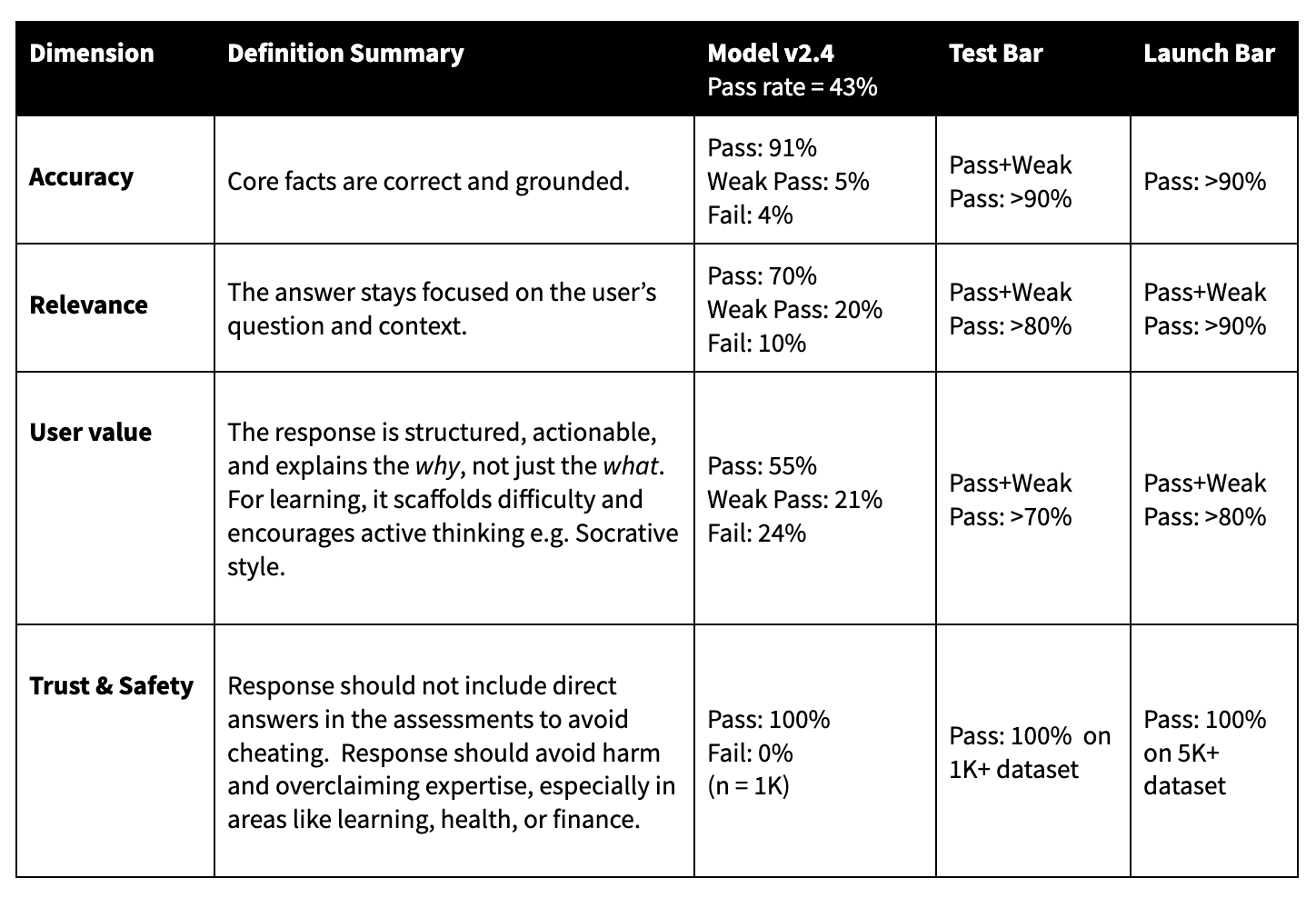
Accuracy – Core facts are correct and grounded.
Relevance – The answer stays focused on the user’s question and context.
User value (i.e. Pedagogy / Helpfulness) – The response is structured, actionable, and explains the why, not just the what. For learning, it scaffolds difficulty and encourages active thinking e.g. Socrative style.
Trust & safety – Response should not include direct answers in the assessments to avoid cheating. Response should avoid harm and overclaiming expertise, especially in areas like learning, health, or finance.
Once these dimensions are defined per use case, they can be rolled up into a simple top-line view: a quality score per dimension. For example, out of 1K samples of outputs, what percentage of outputs pass the bar for Accuracy, Relevance, User Value and Safety. The rest of the eval system exists to measure, monitor, and move those scores over time.
Evals Are a System: Dimensions → Criteria → Launch Bars → Iterations
Once the quality dimensions are clear, the next job is to make them operational.
Most teams have surprisingly strong opinions about quality — they’re just undocumented and inconsistent. A big chunk of the AI PM job is turning that fuzz into something the team can ship against.
I like to think in layers:
Write down what “pass” actually means and iterate. Take a batch of real examples and have a small “labeling party” with cross-functional partners. We argue about what should be considered a pass, a weak pass, or a fail on each dimension. That friction is a feature, not a bug — it forces us to reconcile the model team’s intuition with design, safety, and product goals.
Add adversarial criteria explicitly. It’s not enough that the system behaves well on friendly, well-formed prompts. We also define a separate set of adversarial or borderline cases: people trying to bypass safety, edge cases in policy, tricky prompts that tend to produce unsafe or off-brand content. For those, we set a stricter bar or a separate metric on a larger # of inputs.
Build pre-generation and post-generation model guardrails. Try to treat guardrails before and after generation as part of the model design and development, not an afterthought.
Pre-generation guardrails decide which prompts or inputs we will reject or reframe.
Post-generation guardrails decide which outputs we will filter, rewrite, or block.
For both, measure a “pass rate” and report it along with the quality score. You can achieve a higher quality score by adding stricter guardrails and having a lower pass rate. But you will have to make the tradeoffs on the % of users or traffic that you can cover.

DataDog: LLM guardrails Agree on a testing bar and a launch bar. Before we run any user-facing experiment, we set a testing bar: minimum thresholds on quality score, pass rate, and safety metrics that have to be met offline. Then we set a launch bar: what we need to see in online metrics (and in monitored quality) to roll out more broadly.

5. Connect quality metrics to success metrics. After launch, a critical test of your eval system is whether changes in quality actually show up in business and product outcomes. In practice, the question becomes:
If we improve quality on dimension X by Y%, how much lift do we see in engagement or performance when this model goes to production?
You can run correlation analysis or measure the delta in success metrics when A/B testing two model versions. If higher quality consistently predicts better outcomes, you’re likely tracking the right dimensions — the ones that actually reflect (and reinforce) the PMF of your product.
Human Evals, LLM-as-Judge, and Everything in Between
You can’t talk about evals at scale without talking about people.
Even if you lean heavily on automation, human evaluation is the backbone. That means:
Clear rubrics and examples for each dimension
The right level of expertise in your labelers (e.g., design expertise to evaluate visual style)
Regular calibration so people interpret the rubric consistently
Once the human pipeline is solid, you can start thinking about LLM-as-judge to make this scalable.
A common pattern: use a stronger or more capable model as a judge to rate outputs on things like factuality, prompt adherence, faithfulness to retrieved context, or style constraints. You give the judge model a rubric, a structured output format (e.g., score + explanation), and then you validate its ratings against human labels.
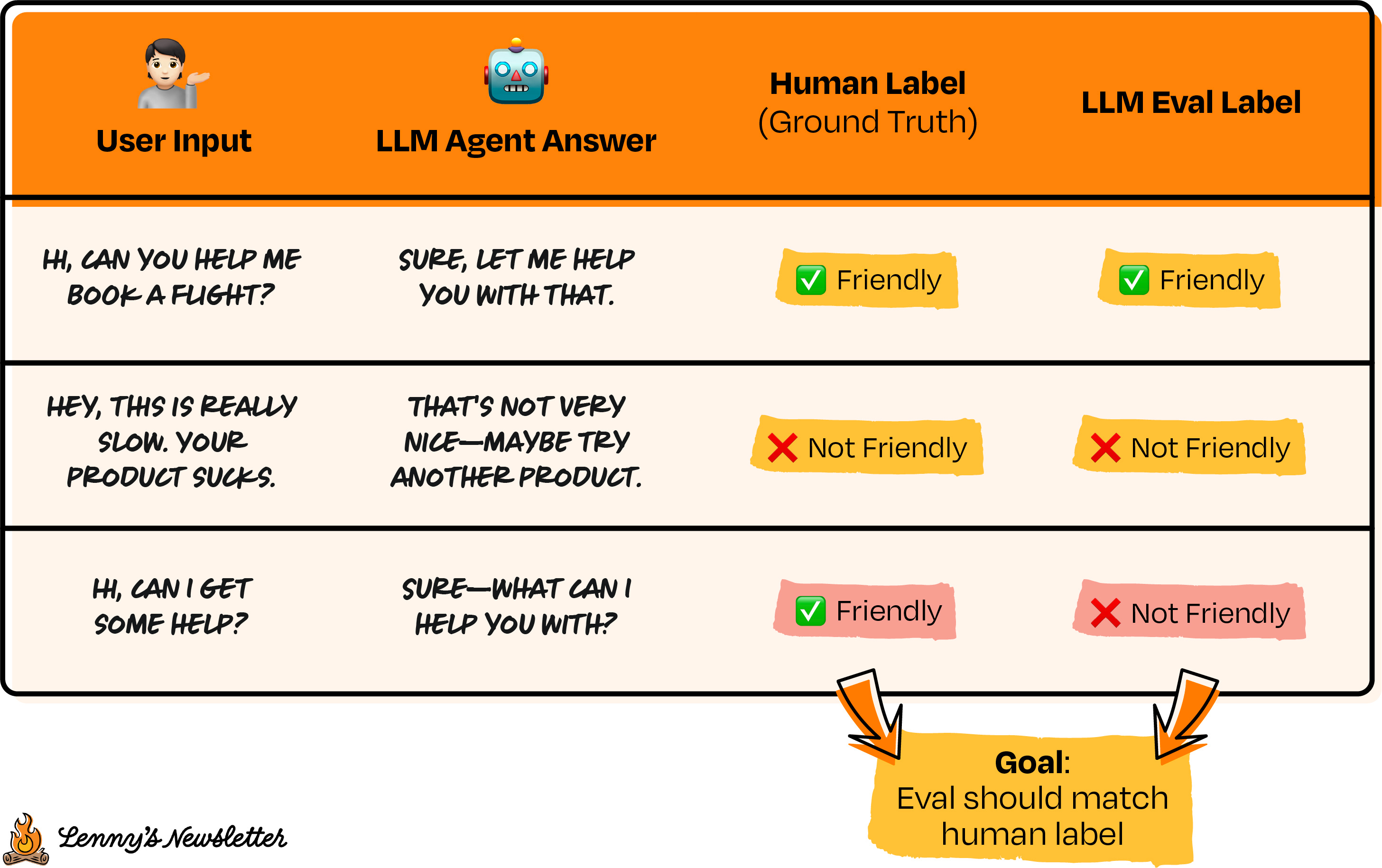
If agreement is high enough, the judge can be used to scale evals and reduce human load. If not, the rubric, instructions, or even the choice of judge model needs to change.
The PM’s role isn’t to write the judge prompt alone, but to:
Make sure the rubric lines up with what actually matters for the product
Deciding where automation is “good enough” and where humans must stay in the loop
Making sure evals are wired into decision-making (launch gates, dashboards, weekly reviews), not just sitting in a notebook somewhere
This is one of those areas where a PM who understands both the product and the evaluation stack can dramatically reduce cost and increase iteration speed.

Hallucination: From Buzzword to Debuggable Risk
“Hallucination” is one of those words that shows up in every AI conversation and almost no two people mean exactly the same thing by it. The working definition I use is:
The model generates content that is factually incorrect, unsupported, or fabricated — in situations where users reasonably expect truth.
That sounds simple, but acting on it requires more structure. It’s not enough to say, “Our model hallucinates less.” You want to know: how often, in which scenarios, and how bad it is when it happens.
Measuring Hallunication
I usually treat hallucination as a risk spectrum:
Grounded and correct
Ambiguous / incomplete / not clearly verifiable
Clearly wrong but low risk
Wrong in a way that can mislead or harm
On one end, the model is fully grounded and correct. In the middle, you have answers that are ambiguous, incomplete, or not clearly verifiable. On the far end, you have answers that are simply wrong — and in the worst case, wrong in a way that can mislead or harm the user (for example, certain kinds of health, self-harm, or financial guidance).
Your tolerance for those different levels will vary by product. In a playful brainstorming tool, you might accept more “creative” deviation. In tools that touch money, health, safety, or kids, your tolerance for anything beyond conservative, grounded answers drops drastically.
Measuring hallucination means combining offline and online signals:
Human eval where raters see prompt + context + answer and score factuality, faithfulness to context, and severity of errors
Small “golden” datasets with known correct answers to run consistent regression tests when models, prompts, or retrieval change
Automatic checks that compare the answer to a knowledge source (retrieved docs, structured knowledge base, or API response) to detect invented details
Explicit user feedback like “report incorrect” or equivalent signals
Spikes or changes in how often post-generation guardrails fire and on what types of prompts
Debugging and Reducing (Not Eliminating) Risk
When hallucinations are found, the instinct is often “we need a better model.” Sometimes that’s right. Often, the issue lives elsewhere in the pipeline:
Retrieval surfacing the wrong documents
Important context being truncated due to length limits
Gaps in the underlying knowledge base
Poorly defined behavior for “I don’t know” scenarios
As a PM, I find it useful to ask:
Are we dealing with a model behavior issue, a context quality issue, or a knowledge coverage issue?
Where do we get the most leverage: improving retrieval, enriching the knowledge base, tuning prompts, or upgrading the base model?
For this product and persona, is it better to answer less often but more faithfully (“I don’t know” more) or to prioritize coverage and accept more aggressive guardrails?
The answer determines whether the team should be working on retrieval, knowledge base, prompts, model upgrades, or simply more conservative product behavior.
Putting it together… Where a PM Actually Moves the Needle in Evals
None of this requires you, as a PM, to be the person implementing eval frameworks or wiring them into CI pipelines. But it does require you to own the shape of the eval system and how it connects to product outcomes.
The places where I’ve seen great PMs add the most value:
Define “good” in context. Can explain, concretely, what quality means for each AI surface, and how that maps to a small set of metrics and thresholds.
Design evals as a product. Treat model teams, safety, leadership, and downstream product teams as “users” of evals with questions they need answered repeatedly. Evals are structured to answer those questions, not just to look impressive.
Connect offline and online. Don’t stop at “the benchmark got better.” Asks whether user satisfaction, retention, task completion, or revenue actually moved, and adjusts the eval strategy when they don’t.
Own risk posture and tradeoffs. Drives clarity on where the product can be playful and where it must be conservative; how that translates into launch bars, ramp strategy, and fallback behavior; and how hallucination and safety risks are monitored over time.
Tell the story. Can walk through an AI feature end-to-end in plain language: how quality was defined, how evals were set up, how testing and launch bars were decided, how issues like hallucination were debugged, and what changed for users and the business.
It’s not just, “We built evals.” It’s:
“Here’s how we defined quality for this capability, here’s the system we built to measure and improve it, and here’s the impact it had.”